PyTorch로 로지스틱 회귀(Logistic Regression) 직접 구현하기
1. 데이터셋 다운로드 및 NumPy로 데이터 로드
import kagglehub
import os
import numpy as np
from kagglehub import KaggleDatasetAdapter
path = kagglehub.dataset_download("uciml/pima-indians-diabetes-database")
print("Path to dataset files:", path)
file_path = os.path.join(path, "diabetes.csv")
# Load the latest version
loaded_data=np.loadtxt(file_path,delimiter=',',skiprows=1)
x_train_np=loaded_data[:,0:-1]
y_train_np=loaded_data[:,[-1]]
print('loaded_data.shape=',loaded_data.shape)
print('x_train_np.shape=',x_train_np.shape)
print('y_train_np.shape=',y_train_np.shape)- KaggleHub를 사용해 Pima Indians Diabetes 데이터셋을 다운로드
- np.loadtxt로 CSV 파일을 NumPy 배열로 로드
- skiprows=1
→ CSV 첫 줄은 컬럼명이므로 학습 데이터에서 제외 - 입력 데이터(x_train_np)
- 마지막 열을 제외한 8개의 특성(feature)
- 정답 데이터(y_train_np)
- 마지막 열(당뇨병 여부, 0 또는 1)
이렇게 분리하는 이유는 머신러닝에서는 입력 X와 정답 y를 명확히 분리해야 모델 학습이 가능하다.
2. NumPy → PyTorch Tensor 변환
import torch
from torch import nn
x_train = torch.Tensor(x_train_np)
y_train = torch.Tensor(y_train_np)
- PyTorch 모델은 Tensor 타입만 연산 가능
- NumPy 배열을 그대로 사용할 수 없기 때문에 torch.Tensor()로 변환
- 이후 연산(Forward, Backward, Optimizer)이 모두 PyTorch 기준으로 수행됨
3. 로지스틱 회귀 모델 정의
class MyLogisticRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.logistic_stack = nn.Sequential(
nn.Linear(8, 1)
)
def forward(self, data):
pred = self.logistic_stack(data)
return pred
- nn.Module을 상속받아 사용자 정의 모델 생성
- nn.Linear(8, 1)
- 입력 특성: 8개
- 출력: 1개 (이진 분류)
- Sigmoid를 사용하지 않은 이유는 뒤에서 BCEWithLogitsLoss를 사용하기 때문
로지스틱 회귀 수식
y = wx + b
PyTorch에서는 이 선형 연산을 nn.Linear 하나로 표현 가능
4. 모델 파라미터 확인
model = MyLogisticRegressionModel()
for param in model.parameters():
print(param)
- 모델이 실제로 어떤 파라미터를 학습하는지 확인
- 출력값:
- 가중치(weight)
- 편향(bias)
학습이 진행되면 이 값들이 계속 업데이트됨
5. 손실 함수와 옵티마이저 설정
loss_function = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)손실 함수
- BCEWithLogitsLoss
- Sigmoid + Binary Cross Entropy를 내부적으로 포함
- 수치적으로 더 안정적
- 이진 분류 문제에 가장 적합
옵티마이저
- Adam
- 학습이 빠르고 안정적
- 실무에서도 가장 많이 사용
- lr=0.001은 기본적으로 무난한 학습률
6. 학습 루프 (Training Loop)
train_loss_list = []
train_accuracy_list = []
nums_epoch = 10000
for epoch in range(nums_epoch + 1):
outputs = model(x_train)
loss = loss_function(outputs, y_train)
train_loss_list.append(loss.item())
pred = outputs > 0.5
correct = (pred.float() == y_train)
accuracy = correct.sum().item() / len(correct)
train_accuracy_list.append(accuracy)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print('epoch=', epoch, 'current loss=', loss.item(), 'accuracy=', accuracy)
- Forward
- 입력 데이터를 모델에 통과시켜 예측값 생성
- Loss 계산
- 예측값과 실제값 비교
- Accuracy 계산
- 0.5 기준으로 True / False 분류
- Backward
- loss.backward()로 기울기 계산
- Optimizer step
- 가중치 업데이트
optimizer.zero_grad()
→ 이전 epoch의 gradient 누적 방지
7. 학습 결과 출력 로그
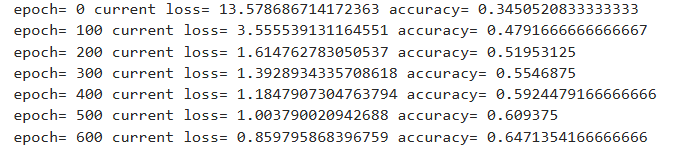
- 초기에는 loss가 매우 크고 정확도도 낮음
- 학습이 진행되면서
- Loss 감소
- Accuracy 증가
- 최종 정확도 약 76% 수준
로지스틱 회귀 + 단순 학습만으로도 꽤 의미 있는 결과
8. 학습 후 파라미터 확인
for param in model.parameters():
print(param)
- 학습 전과 비교하면 가중치와 bias가 확연히 달라짐
- 모델이 데이터의 패턴을 학습했다는 증거
9. Loss 변화 시각화
import matplotlib.pyplot as plt
plt.title("Loss Trend")
plt.xlabel("epochs")
plt.ylabel("loss")
plt.grid()
plt.plot(train_loss_list, label="train loss")
plt.legend(loc='best')
plt.show()
- Epoch이 증가할수록 loss가 안정적으로 감소
- 학습이 정상적으로 수렴하고 있음을 확인 가능
10/ Accuracy 변화 시각화
plt.title("Loss Trend")
plt.xlabel("epochs")
plt.ylabel("loss")
plt.grid()
plt.plot(train_accuracy_list, label="train accuracy")
plt.legend(loc='best')
plt.show()
- 초반 급격한 정확도 상승
- 이후 완만하게 증가하며 수렴
마무리 정리
- PyTorch로 로지스틱 회귀를 처음부터 직접 구현
- 데이터 로드 → 모델 정의 → 학습 → 시각화 전체 흐름 이해
'현장실습 일기' 카테고리의 다른 글
| 2주차 회고 - 딥러닝(Deep Learning)의 본질: '깊은' 신경망의 힘 (0) | 2026.01.22 |
|---|---|
| 현장실습 2주차 회고 (0) | 2026.01.22 |
| 1주차 회고 – Oxford-IIIT Pet Dataset으로 CLIP 적용하기 (0) | 2026.01.11 |
| 1주차 회고 – CLIP 모델 첫 구현과 Zero-shot 분류 실험 (0) | 2026.01.11 |
| 현장실습 1주차 회고 (0) | 2026.01.11 |