딥러닝을 공부할 때 가장 먼저 접하게 되는 '교과서' 같은 데이터셋이 있습니다. 바로 MNIST입니다. 이 데이터를 활용해 인공지능이 어떻게 숫자를 인식하는지 그 과정을 PyTorch 코드로 상세히 파헤쳐 보았습니다.
1. MNIST 데이터셋이란?
MNIST (Modified National Institute of Standards and Technology) 데이터셋은 0부터 9까지의 손글씨 숫자로 이루어진 대규모 데이터베이스입니다.
- 구성: 60,000개의 학습 데이터와 10,000개의 테스트 데이터로 이루어져 있습니다.
- 규격: 각 이미지는 $28 \times 28$ 픽셀의 흑백 이미지이며, 각 픽셀은 0(검은색)부터 255(흰색)까지의 밝기 값을 가집니다.
- 상징성: 머신러닝계의 'Hello World'라고 불릴 만큼, 새로운 알고리즘의 성능을 검증하는 표준으로 오랫동안 사랑받아 왔습니

2. 데이터 설계: "나누고, 섞고, 묶어라"
좋은 모델을 만들기 위해서는 데이터를 단순히 넣는 것이 아니라 전략적으로 관리해야 합니다.
2-1. 훈련, 검증, 테스트의 삼박자
작성하신 코드에서는 전체 6만 개의 데이터를 다음과 같이 나눕니다.
- Train (51,000): 모델이 실제로 공부하며 가중치를 업데이트하는 데이터입니다.
- Validation (9,000): 학습 도중 "공부가 잘되고 있나?"를 확인하는 중간 점검용입니다. 이 결과를 보고 하이퍼파라미터를 수정합니다.
- Test (10,000): 모든 학습이 끝난 후, 실전 성능을 측정하는 최종 시험입니다.
2-2. DataLoader: 효율적인 학습을 위한 '급식소'
BATCH_SIZE=32
train_dataset_loader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
- Batch Size (32): 5만 개를 한 번에 공부하면 모델이 과부하에 걸릴 수 있습니다. 32개씩 끊어서 공부하며 효율을 높입니다.
- Shuffle (True): 데이터의 순서를 무작위로 섞어 모델이 특정 순서를 외우지 못하게 합니다.
3. 전체 코드
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import random_split
from torch.utils.data import Dataset, DataLoader
train_dataset=datasets.MNIST(root="MNIST_data/",train=True, # 학습 데이터
#Totenser함수를 사용하면 0~1 사이의 실수들로 바꿔주면서 계산하기 쉽게 만들어준다. 그리고 텐서타입으로 반환해줌
transform=transforms.ToTensor(), # 0~255까지의 값을 0~1 사이의 값으로 변환시켜줌
download=True)
test_dataset=datasets.MNIST(root="MNIST_data/",train=False, # 테스트 데이
transform=transforms.ToTensor(), # 0~255까지의 값을 0~1 사이의 값으로 변환시켜줌
download=True)
print(len(train_dataset))
60000
print(len(test_dataset))
10000
train_dataset_size=int(len(train_dataset)*0.85)
validation_dataset_size=int(len(train_dataset)*0.15)
train_dataset,validation_dataset=random_split(train_dataset,[train_dataset_size,validation_dataset_size])
print(len(train_dataset), len(validation_dataset), len(test_dataset))
51000 9000 10000
class MyDeepLearningModel(nn.Module):
def __init__(self):
super().__init__()
self.flatten=nn.Flatten()
self.fc1=nn.Linear(784,256)
self.relu=nn.ReLU()
self.dropout=nn.Dropout(0.3)
self.fc2=nn.Linear(256,10)
def forward(self, data):
data=self.flatten(data)
data=self.fc1(data)
data=self.relu(data)
data=self.dropout(data)
logits=self.fc2(data)
return logits
BATCH_SIZE=32
train_dataset_loader=DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
validation_dataset_loader=DataLoader(dataset=validation_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_dataset_loader=DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
model=MyDeepLearningModel()
loss_function=nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(), lr=1e-2)
def model_train(dataloader, model, loss_function, optimizer):
model.train() # 신경망을 학습모드(모델 파라미터를 업데이트하는 모드로)로 전환
train_loss_sum=train_correct=train_total=0
total_train_batch=len(dataloader)
for images, labels in dataloader:
x_train=images.view(-1,28*28) # 처음 크기는 (batch_size, 1,28,28)인데 이걸 (batch_size, 784)로 변환
y_train=labels
outputs=model(x_train) # 입력 데이터에 대해 예측 값 계산
loss=loss_function(outputs, y_train) # 모델 예측 값과 정답과의 오차인 손실함수 계산
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_sum+=loss.item()
train_total+=y_train.size(0)
train_correct+=((torch.argmax(outputs,1)==y_train)).sum().item()
train_avg_loss=train_loss_sum/total_train_batch #학습 데이터 평균 오차 계산
train_avg_accuracy=100*train_correct/train_total # 학습데이터 평균 정확도 게산
return (train_avg_loss, train_avg_accuracy)
def model_evaluate(dataloader, model, loss_function, optimizer):
model.eval() # 신경망을 추론모드로 전환
with torch.no_grad(): # 미분 하지 않겠다는 코드 즉 모델 파라미터를 업데이트 시키지 않겠다는 의미
val_loss_sum=val_correct=val_total=0
total_val_batch=len(dataloader)
for images, labels in dataloader: # images에는 MNIST 이미지, labels에는 0~9 정답 숫자
x_val=images.view(-1,28*28) # 처음 크기는 (batch_size, 1,28,28)인데 이걸 (batch_size, 784)로 변환
y_val=labels
outputs=model(x_val)
loss=loss_function(outputs, y_val)
val_loss_sum+=loss.item()
val_total+=y_val.size(0)
val_correct+=((torch.argmax(outputs, 1)==y_val)).sum().item()
val_avg_loss=val_loss_sum/total_val_batch # 검증데이터 평균 오차 계산
val_avg_accuracy=100*val_correct/val_total # 검증 데이터 평균 정확도 계산
return (val_avg_loss, val_avg_accuracy)
train_loss_list=[]
train_accuracy_list=[]
val_loss_list=[]
val_accuracy_list=[]
EPOCH=20
for epoch in range(EPOCH):
#===========model train=============
train_avg_loss, train_avg_accuracy=model_train(train_dataset_loader,
model,loss_function,
optimizer)
train_loss_list.append(train_avg_loss)
train_accuracy_list.append(train_avg_accuracy)
#-----------------------------------
#===========model evaluation========
val_avg_loss, val_avg_accuracy=model_evaluate(validation_dataset_loader,
model, loss_function,
optimizer)
val_loss_list.append(val_avg_loss)
val_accuracy_list.append(val_avg_accuracy)
print(f'epoch:{epoch}, train loss={train_avg_loss}, train accuracy={train_avg_accuracy}, val loss={val_avg_loss}, val accuracy={val_avg_accuracy}')
epoch:0, train loss=0.9801464274693912, train accuracy=77.03333333333333, val loss=0.4576594428496158, val accuracy=88.36666666666666
epoch:1, train loss=0.43575271577989144, train accuracy=87.72941176470589, val loss=0.3498166104950381, val accuracy=90.47777777777777
epoch:2, train loss=0.3644874161728652, train accuracy=89.60980392156863, val loss=0.30739057418091076, val accuracy=91.6
epoch:3, train loss=0.32238478469691584, train accuracy=90.82156862745099, val loss=0.27868536130544985, val accuracy=92.4
epoch:4, train loss=0.294447719761015, train accuracy=91.65882352941176, val loss=0.25568844720139994, val accuracy=92.91111111111111
epoch:5, train loss=0.27096652550157746, train accuracy=92.38823529411765, val loss=0.23941183722980902, val accuracy=93.16666666666667
epoch:6, train loss=0.2514003829415911, train accuracy=92.88235294117646, val loss=0.22217259458299224, val accuracy=93.84444444444445
epoch:7, train loss=0.2360796409692975, train accuracy=93.27450980392157, val loss=0.20950249758225384, val accuracy=94.18888888888888
epoch:8, train loss=0.2215461977856839, train accuracy=93.77254901960784, val loss=0.1989852928932994, val accuracy=94.5111111111111
epoch:9, train loss=0.2100676079181349, train accuracy=94.17450980392157, val loss=0.18825880632280034, val accuracy=94.62222222222222
epoch:10, train loss=0.19935951428546322, train accuracy=94.3529411764706, val loss=0.17928070510929148, val accuracy=95.0111111111111
epoch:11, train loss=0.1907167539825497, train accuracy=94.64313725490196, val loss=0.17234331148128348, val accuracy=95.2
epoch:12, train loss=0.1811797786422233, train accuracy=94.85098039215686, val loss=0.16591329714085193, val accuracy=95.5
epoch:13, train loss=0.17282068151910526, train accuracy=95.12745098039215, val loss=0.1595339657910538, val accuracy=95.4888888888889
epoch:14, train loss=0.16772893399124034, train accuracy=95.23333333333333, val loss=0.1530728926089533, val accuracy=95.73333333333333
epoch:15, train loss=0.16029620828595448, train accuracy=95.50980392156863, val loss=0.1482701521673973, val accuracy=96.0111111111111
epoch:16, train loss=0.1540753280620092, train accuracy=95.6470588235294, val loss=0.14427426107333485, val accuracy=96.14444444444445
epoch:17, train loss=0.1494620611746252, train accuracy=95.67843137254901, val loss=0.14024397007566183, val accuracy=96.12222222222222
epoch:18, train loss=0.14349487275551243, train accuracy=95.90588235294118, val loss=0.13517580503029814, val accuracy=96.27777777777777
epoch:19, train loss=0.1399755400034086, train accuracy=96.07058823529412, val loss=0.13144204594485515, val accuracy=96.27777777777777def model_test(dataloader, model):
model.eval()
with torch.no_grad(): # 미분 하지 않겠다는 코드 즉 모델 파라미터를 업데이트 시키지 않겠다는 의미
test_loss_sum=test_correct=test_total=0
total_test_batch=len(dataloader)
for images, labels in dataloader: # images에는 MNIST 이미지, labels에는 0~9 정답 숫자
x_test=images.view(-1,28*28) # 처음 크기는 (batch_size, 1,28,28)인데 이걸 (batch_size, 784)로 변환
y_test=labels
outputs=model(x_test)
loss=loss_function(outputs, y_test)
test_loss_sum+=loss.item()
test_total+=y_test.size(0)
test_correct+=((torch.argmax(outputs, 1)==y_test)).sum().item()
test_avg_loss=test_loss_sum/total_test_batch # 검증데이터 평균 오차 계산
test_avg_accuracy=100*test_correct/test_total # 검증 데이터 평균 정확도 계산
return (test_avg_loss, test_avg_accuracy)
test_loss,test_accuracy=model_test(test_dataset_loader, model)
print(f'accuracy:{test_accuracy}')
print(f'loss:{test_loss}')
accuracy:96.5
loss:0.12182765494817838
loss:0.12182765494817838
import matplotlib.pyplot as plt
plt.title("Loss Trend")
plt.xlabel("epochs")
plt.ylabel("loss")
plt.grid()
plt.plot(train_loss_list, label="train loss")
plt.plot(val_loss_list, label="val loss")
plt.legend(loc='best')
plt.show()

plt.title("Accuracy Trend")
plt.xlabel("epochs")
plt.ylabel("loss")
plt.grid()
plt.plot(train_accuracy_list, label="train accuracy")
plt.plot(val_accuracy_list, label="val accuracy")
plt.legend(loc='best')
plt.show()

4. 코드 상세 분석
이 코드는 데이터 전처리 -> 모델 정의 -> 학습(Train) -> 검증(Validation) -> 테스트(Test)로 이어지는 전형적인 딥러닝 워크플로우를 따르고 있습니다.
① 데이터셋 분할과 로더 (Data Strategy)
train_dataset_size = int(len(train_dataset) * 0.85)
validation_dataset_size = int(len(train_dataset) * 0.15)
train_dataset, validation_dataset = random_split(train_dataset, [train_dataset_size, validation_dataset_size])
- random_split: 60,000개의 데이터를 85:15 비율로 나눕니다.
- Train(51,000): 모델이 가중치를 업데이트하는 '공부용'입니다.
- Validation(9,000): 학습 도중 과적합 여부를 판단하는 '모의고사'입니다.
- DataLoader: 데이터를 BATCH_SIZE=32만큼 묶어 모델에 공급합니다. 한 번에 모든 데이터를 넣지 않고 조금씩 나누어 넣음으로써 메모리 효율을 높이고, 경사하강법의 성능을 개선합니다.
② 신경망 모델 설계 (Model Architecture)
class MyDeepLearningModel(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() # 1. 2D -> 1D 변환
self.fc1 = nn.Linear(784, 256) # 2. 첫 번째 은닉층
self.relu = nn.ReLU() # 3. 활성화 함수
self.dropout = nn.Dropout(0.3) # 4. 과적합 방지
self.fc2 = nn.Linear(256, 10) # 5. 출력층
- nn.Flatten(): 28 x 28 크기의 이미지를 784개의 연속된 숫자로 펼칩니다.
- nn.Linear(784, 256): 784개의 입력을 받아 256개의 특징을 추출합니다. 이 과정에서 784 x 256개의 가중치(W)가 생성됩니다.
- nn.ReLU(): 은닉층 뒤에 배치되어 모델에 비선형성을 부여합니다. 복잡한 형태의 숫자를 인식할 수 있게 해주는 핵심 엔진입니다.
- nn.Dropout(0.3): 학습 시 뉴런의 30%를 무작위로 끕니다. 모델이 특정 뉴런에만 의존하지 않고 전체적으로 골고루 학습하게 하여 일반화 성능을 높입니다.
- nn.Linear(256, 10): 마지막으로 10개의 숫자(0~9)에 대한 점수를 산출합니다.
③ 손실 함수와 최적화 도구 (Loss & Optimizer)
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
- CrossEntropyLoss: 모델의 예측값(Softmax 확률값)과 실제 정답(Label) 사이의 차이를 계산합니다. 다중 분류 문제에서 가장 표준적으로 사용됩니다.
- SGD: 계산된 오차(Loss)를 바탕으로 모델의 파라미터를 어느 방향으로 수정할지 결정합니다. lr=1e-2(0.01)은 한 번에 수정할 보폭의 크기입니다.
④ 학습 루프: model_train 함수의 핵심
model.train() # 학습 모드 활성화
for images, labels in dataloader:
x_train = images.view(-1, 28*28) # 데이터 형태 맞추기
outputs = model(x_train) # 순전파 (Forward)
loss = loss_function(outputs, y_train) # 오차 계산
optimizer.zero_grad() # 이전 기울기 초기화
loss.backward() # 역전파 (Backpropagation)
optimizer.step() # 가중치 업데이트 (Step)
- optimizer.zero_grad(): 파이토치는 가중치를 업데이트할 때 기울기를 누적하기 때문에, 매 배치마다 초기화해 주어야 정확한 학습이 가능합니다.
- loss.backward(): 이 미분 과정을 통해 각 층의 가중치가 오차에 얼마나 기여했는지 계산합니다.
⑤ 검증 및 성능 평가 (Evaluation)
model.eval() # 추론 모드 활성화
with torch.no_grad(): # 미분 중단
# ... 오차 및 정확도 계산 ...
- model.eval(): 학습 시 사용했던 Dropout을 끕니다. 평가할 때는 모든 뉴런을 다 사용해야 하기 때문입니다.
- torch.no_grad(): 평가 시에는 가중치를 업데이트할 필요가 없으므로 연산 속도를 높이고 메모리를 절약하기 위해 미분 계산을 중단합니다.
- torch.argmax(outputs, 1): 10개의 출력값 중 가장 점수가 높은 인덱스를 찾아 모델의 최종 예측값으로 결정합니다.
5. 학습 결과 및 그래프 해석

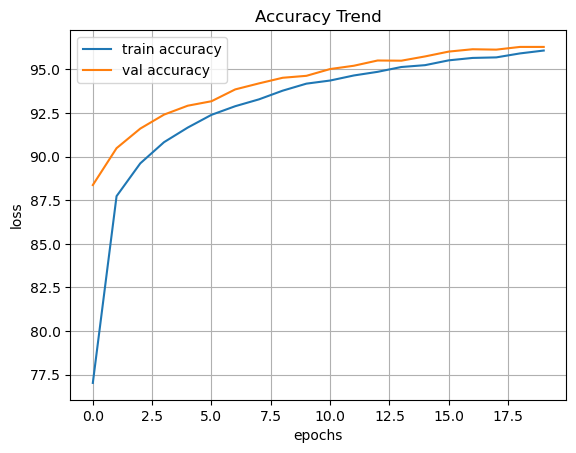
최종적으로 Test Accuracy 96.5%라는 결과를 얻었습니다.
- Loss Trend: Train Loss와 Val Loss가 모두 안정적으로 우하향합니다. 만약 Val Loss만 튀어 오른다면 과적합(Overfitting)이 발생한 것인데, 이 모델은 Dropout 덕분에 매우 안정적입니다.
- Accuracy Trend: 학습 초기에 정확도가 급격히 상승하다가 점차 수렴하는 모습을 보입니다. 20 Epoch만으로도 충분히 높은 성능에 도달했음을 확인할 수 있습니다.
'현장실습 일기' 카테고리의 다른 글
| 현장실습 3주차 회고 (0) | 2026.01.27 |
|---|---|
| 2주차 회고 -FashionMNIST로 비교하는 MLP vs CNN 성능 차이 분석 (1) | 2026.01.22 |
| 2주차 회고 - 딥러닝(Deep Learning)의 본질: '깊은' 신경망의 힘 (0) | 2026.01.22 |
| 현장실습 2주차 회고 (0) | 2026.01.22 |
| 1주차 회고 – Oxford-IIIT Pet Dataset으로 CLIP 적용하기 (0) | 2026.01.11 |