전에는 단순히 0~9까지의 손글씨 데이터가 있는 MNIST를 사용하였습니다.
이번에는 FashionMNIST 데이터셋을 활용하여 일반적인 딥러닝 모델(MLP)과 이미지 처리에 특화된 합성곱 신경망(CNN)의 성능 차이를 심층 분석해 보았습니다.
1. FashionMNIST 데이터셋이란?
MNIST가 손글씨 숫자였다면, FashionMNIST는 운동화, 셔츠, 가방 등 10가지 종류의 패션 아이템으로 구성된 데이터셋입니다.
- 크기: 28 x 28 픽셀 (흑백)
- 특징: 숫자 데이터보다 형태가 복잡하고 경계선이 다양하여, 일반적인 MLP로는 높은 정확도를 얻기가 더 까다롭습니다.

2. MLP와 CNN의 구조 차이
단순 딥러닝 (MLP) 구조
가장 기본적인 형태인 다층 퍼셉트론(Multi-Layer Perceptron)입니다.
- 특징: 이미지를 1차원으로 길게 펼쳐서(Flatten) 입력합니다.
- 한계: 이미지를 한 줄로 세우다 보니 픽셀 간의 공간적 구조(예: 소매와 몸통의 연결성) 정보가 손실됩니다.
합성곱 신경망 (CNN) 구조
이미지의 특징을 추출하는 데 최적화된 CNN 모델입니다.
CNN이 강력한 이유:
- 커널(Kernel/Filter): 이미지의 국소적인 부분(가로선, 세로선, 질감 등)을 훑으며 특징을 추출합니다.
- 풀링(Pooling): 중요한 정보만 남기고 데이터 크기를 줄여 모델이 사소한 변화(이미지가 약간 치우침 등)에 강해지도록 만듭니다.
- 공간 정보 유지: 이미지를 펼치지 않고 2차원 그대로 학습하므로 형태를 훨씬 잘 이해합니다.
3. 전체 코드
코드가 다소 길어지는 관계로 링크 첨부 하였습니다.
https://github.com/docodocod/ML-DL/blob/main/DL/fashionMNIST.ipynb
ML-DL/DL/fashionMNIST.ipynb at main · docodocod/ML-DL
Contribute to docodocod/ML-DL development by creating an account on GitHub.
github.com
4.코드 상세 분석
두 모델 모두 데이터 준비 단계는 동일하지만, 딥러닝의 기초가 되는 매우 중요한 부분입니다.
train_dataset = datasets.FashionMNIST(root='FashionMNIST_data/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.FashionMNIST(root='FashionMNIST_data/', train=False, transform=transforms.ToTensor(), download=True)
- transforms.ToTensor(): 가장 중요한 전처리입니다. 0~255 사이의 픽셀 강도 값을 0~1 사이의 실수값으로 정규화(Normalization)하고, 데이터를 파이토치 연산에 최적화된 Tensor 형태로 변환합니다.
- random_split: 데이터를 훈련용(85%)과 검증용(15%)으로 분리합니다. 모델이 훈련 데이터에만 익숙해지는 '과적합'을 방지하고, 중간중간 실력을 테스트하기 위함입니다.
- DataLoader: 데이터를 BATCH_SIZE=32 단위로 쪼개서 공급합니다. 이는 메모리 절약뿐만 아니라, 가중치를 더 자주 업데이트하게 하여 학습의 효율을 높입니다.
[MLP 모델: 선형적인 정보 처리]
class MyDeepLearningModel(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() # (1, 28, 28) 이미지를 784개의 긴 줄로 만듦
self.fc1 = nn.Linear(784, 256) # 784개의 특징 -> 256개의 특징으로 압축
self.reLU = nn.ReLU() # 비선형성 추가
self.dropout = nn.Dropout(0.3) # 과적합 방지 (뉴런 30% 끄기)
self.fc2 = nn.Linear(256, 10) # 최종 10개 클래스로 판별
- 작동 방식: 이미지를 단순히 '숫자의 집합'으로 봅니다. 픽셀 간의 위치 관계보다는 각 픽셀값이 가지는 통계적인 빈도를 학습합니다.
[CNN 모델: 공간 정보를 보존하는 특징 추출]
class MyCNNModel(nn.Module):
def __init__(self):
super().__init__()
# 1차 특징 추출: 3x3 필터 32개 사용
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1)
# 2차 특징 추출: 3x3 필터 64개 사용
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1)
# 정보 압축: 크기를 절반으로 줄임 (2x2 Max Pooling)
self.pooling = nn.MaxPool2d(kernel_size=2, stride=2)
# 분류기 (Fully Connected Layer)
self.fc1 = nn.Linear(7*7*64, 256)
self.fc2 = nn.Linear(256, 10)
- 핵심 연산: Conv2d가 이미지 위를 훑으며 선, 면, 복잡한 문양 등의 특징 지도(Feature Map)를 생성합니다. view(-1, 7*7*64) 부분은 추출된 2차원 특징들을 최종 분류를 위해 1차원으로 변환하는 과정입니다.
학습 및 검증 루프 (Training & Evaluation)
두 코드에서 공통적으로 사용된 핵심 함수들입니다.
① model_train (학습)
- model.train(): 모델을 학습 모드로 전환합니다. Dropout이 활성화되어 과적합을 방지합니다.
- optimizer.zero_grad(): 딥러닝은 기울기를 누적하는 성질이 있습니다. 새로운 배치마다 이전의 기울기를 지워줘야 정확한 학습 방향을 잡습니다.
- loss.backward(): 역전파(Backpropagation)입니다. 출력층에서 발생한 오차를 입력층까지 거꾸로 전달하며 각 가중치가 오차에 기여한 정도를 계산합니다.
- optimizer.step(): 계산된 기울기를 바탕으로 가중치를 실제로 업데이트합니다.
② model_evaluate / model_test (평가)
- model.eval(): 평가 모드로 전환합니다. Dropout을 비활성화하여 모든 뉴런의 지식을 총동원합니다.
- with torch.no_grad(): 가중치를 업데이트하지 않으므로 미분 계산을 끕니다. 메모리 사용량을 대폭 줄이고 연산 속도를 높입니다.
최적화 도구 (Optimizer)의 차이
이 부분이 성능 차이의 숨은 조역입니다.
- MLP (SGD): torch.optim.SGD. 전통적인 방식으로, 일정한 학습률로 경사를 따라 내려갑니다. 안정적이지만 최적점에 도달하는 속도가 느릴 수 있습니다.
- CNN (Adam): torch.optim.Adam. 방향뿐만 아니라 속도까지 스스로 조절하는 영리한 옵티마이저입니다. 이 덕분에 CNN이 훨씬 빠르게 99%라는 경이로운 정확도에 도달할 수 있었습니다.
5. 결과 해석 및 결론 분석
MLP vs CNN 손실도


MLP vs CNN 정확도

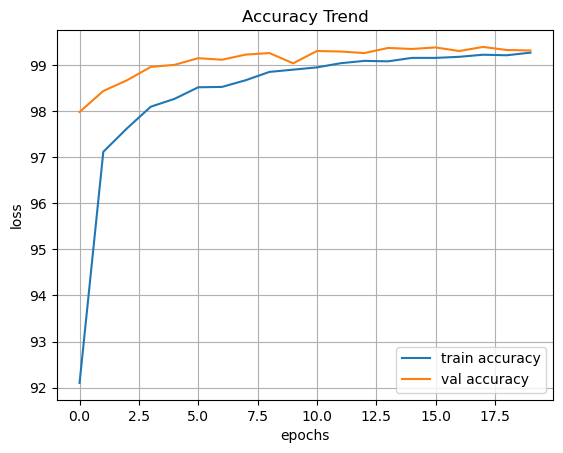
- 정확도 (Accuracy): MLP(86.75%) vs CNN(99.42%).
- CNN은 이미지를 있는 그대로 인식하기 때문에 복잡한 의류 패턴을 거의 완벽하게 구분해 냈습니다.
- 손실 (Loss): MLP는 손실값이 줄어드는 속도가 더디지만, CNN은 학습 초반에 이미 손실값이 0에 가깝게 급감합니다.
- 성능 요인:
- CNN의 특징 추출(Feature Extraction) 능력.
- Adam 옵티마이저의 효율적인 가중치 업데이트.
- GPU(CUDA)를 활용한 대규모 행렬 연산 처리.
6. 후기
코드 전체를 비교해 본 결과 MLP는 이미지를 숫자로만 보지만 CNN은 이미지를 '형태'로 이해하기 때문에 이미지 데이터에는 CNN이 압도적으로 유리하다는 결론을 얻었습니다.
'현장실습 일기' 카테고리의 다른 글
| 현장실습 3주차 회고 (0) | 2026.01.27 |
|---|---|
| 2주차 회고 - 딥러닝의 Hello World: MNIST 손글씨 숫자 분류하기 (1) | 2026.01.22 |
| 2주차 회고 - 딥러닝(Deep Learning)의 본질: '깊은' 신경망의 힘 (0) | 2026.01.22 |
| 현장실습 2주차 회고 (0) | 2026.01.22 |
| 1주차 회고 – Oxford-IIIT Pet Dataset으로 CLIP 적용하기 (0) | 2026.01.11 |